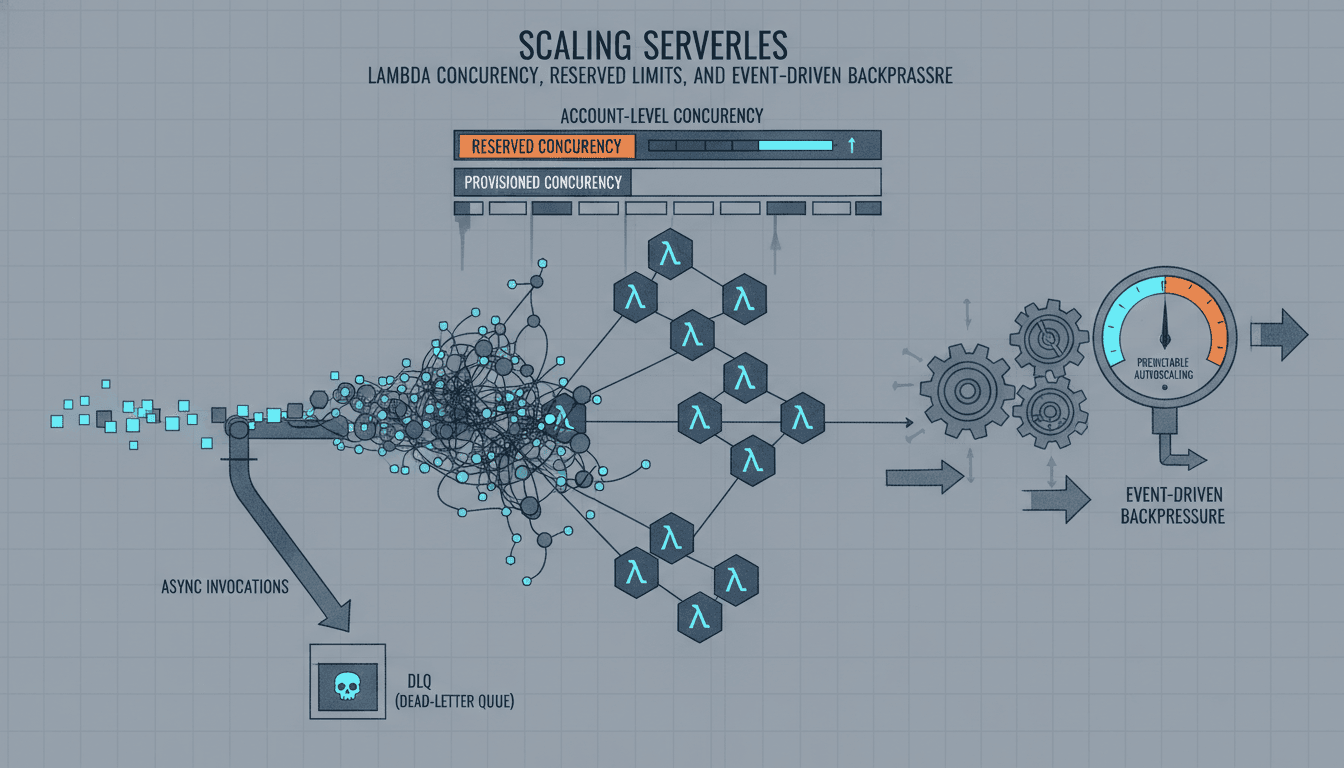
Lambda scales by launching execution environments, but account concurrency caps, downstream rate limits, and DynamoDB throttling can turn “infinite scale” into sudden throttling. Design backpressure and partial failure from the start.

Guards that pay off

- Request a concurrency limit raise before launch day; load test to find your real plateau.
- Use SQS with batching and visibility timeouts to absorb spikes instead of synchronous fan-out chains.
- Monitor asynchronous invocation destinations and dead-letter queues—silent drops are worse than loud failures.
In 2026, pairing Lambda with Step Functions for human-in-the-loop or long workflows is often clearer than chaining dozens of functions by time alone.
How operators translate this into delivery
When initiatives touch scaling serverless, the bottleneck is rarely syntax—it is clarity on ownership, budgets, and definitions of done. Schedule explicit checkpoints between product marketing, engineering, and security so nobody discovers mismatched assumptions during launch week. Prefer thin slices that prove instrumentation and rollback before you widen scope; that discipline is what Search and internal wikis reward in 2026 when people look for authoritative write-ups tied to aws lambda concurrency scaling limits.
Finance and compliance teams increasingly ask how work tied to cost-aware scaling, resilience, least-privilege access, and operational ownership across accounts and environments maps to ROI. Keep a living one-pager with baseline metrics (conversion paths, incident rate, deployment interval, ticket age) so you can attribute improvements to specific releases—not to vanity dashboards. Capture architecture notes and threat-model fragments where new teammates search first; ambiguity there becomes expensive production risk later.
Alignment questions to answer early
- Who signs off when scaling serverless affects customer data or SLAs—and on what cadence do they review drift?
- Which environments must mirror production telemetry (including synthetic checks) before executives greenlight rollout?
- What single metric or qualitative signal rolls up to leadership so progress is legible without cherry-picking?
- Where will operators look up the canonical runbook six months from now—wiki, ticketing, or chat—and who keeps it fresh?
Measurement, documentation, and long-term SEO value
Treat this page as living documentation: refresh examples, screenshots, and statistics on a predictable schedule so search engines and coworkers see freshness. Internal search and external search both reward specificity—link to sibling posts in the toolwork.dev blog cluster when concepts overlap (aws lambda concurrency scaling limits adjacent topics belong in context). When AI-generated summaries appear on SERPs, concise headings and factual bullets increase the odds your narrative survives extraction faithfully.
If your roadmap stacks multiple bets (cost-aware scaling, resilience, least-privilege access, and operational ownership across accounts and environments), sequence them so analytics and logs prove each layer before you pile on complexity. Escalate exceptions early—latency regressions, crawl anomalies, OAuth scopes widening—rather than patching silently; institutional memory decays faster than code churn.